
Machine learning can be used to detect fraud in a variety of industries, including banking, insurance, and healthcare. It can also be used to detect fraud in online transactions, such as credit card fraud and identity theft.
The things people used to buy at shops years ago are now purchased online, no matter what they are: furniture, food, or clothes. As a result, the global E-Commerce market is rapidly rising and estimated to reach $4.9 trillion by 2021. This undoubtedly triggers members of the criminal world to find paths to victims’ wallets through the Web.
We, at SPD Technology, have years of experience in Fraud Detection using Machine Learning for some of our major clients. In this article, we would like to share our insights on this topic.
Fraud Detection with Machine Learning
“Artificial intelligence would be the ultimate version of Google. The ultimate search engine that would understand everything on the web. It would understand exactly what you wanted, and it would give you the right thing. We’re nowhere near doing that now. However, we can get incrementally closer to that, and that is basically what we work on.” — Larry Page, the co-founder and developer of Google.

Fraud Detection powered by AI solutions development becomes possible due to the ability of Machine Learning algorithms to learn from historical fraud patterns and recognize them in future transactions. Machine Learning algorithms appear more effective than humans when it comes to the speed of information processing. Also, ML algorithms are able to find sophisticated fraud traits that a human simply cannot detect.
Works faster. Rule-based fraud prevention systems imply creating exact written rules to “tell” the algorithm which types of operations seem normal and should be permitted, and which shouldn’t be because they seem suspicious. However, writing rules takes a lot of time. Also, manual interaction in the E-Commerce world is so dynamic that things can change significantly within a few days. Here Machine Learning fraud detection methods will come in handy to learn new patterns.
Scale. ML methods show a better performance along with the growth of the dataset to which they are fitted — meaning the more samples of fraudulent operations they are trained on, the better they recognize fraud. This principle does not apply to rule-based systems as long as they never evolve themselves. Also, a data science team should be aware of the risks linked to fast model scaling; if the model did not detect fraud and marked it incorrectly, this will lead to false negatives in future.
Efficiency. Machines can take over routine tasks and the repetitive work of manual fraud analysis, and the specialists will be able to spend time on making more high-level decisions.
Don't have time to read?
Book a free meeting with our experts to discover how we can help you.
Book a MeetingMachine Learning Fraud Detection Models
Email Phishing Detection Models
Phishing emails represent spam letters that have fraudulent intentions. Phishers make fake websites and their URLs highly similar, both visually and semantically, to the originals. They are mostly threats to the Banking sector, multinational companies, and even medical establishments.
Logistic Regression is one of classic Machine Learning algorithms for phishing detection. Logistic Regression uses a linear model to predict a number in range from “0” or “1”, meaning spam or not.
Another way is to extract features from a website and classify it as fake or not with traditional Machine Learning classification models such as SVM, Naive Bayes, and Extreme Learning Machine. The first stage before classification includes NLP to process the text from a website and provide a semantic analysis of the text.
Generally, phishing detection is tackled as a supervised Machine Learning problem that involves collecting a number of falsified emails with fake URLs and an equal number of legit emails and websites from the original sources in order to train the model. The features that most obviously contribute to the classification of an email as “phishing” or not are: usage of the “at” symbol in the URL address, so that the browser cannot read symbols before “at”, or the favicon shown in the address bar is downloaded from a domain other than the one shown in the address bar. Also, the registration length of the site identifies whether the site is fake, because trustworthy resources most likely will register their domains for a long time, unlike phishing websites.
Indicators for phishing fraud detection with Machine Learning are shown in the table below:
| # | Feature | Significance |
|---|---|---|
| 1 | Having IP address | High |
| 2 | URL length | Medium |
| 3 | Having “at” symbol | Low |
| 4 | Double slash redirecting | Medium |
| 5 | Having subdomain | Medium |
| 6 | Domain registration length | Medium |
| 7 | Favicon | Medium |
| 8 | HTTPS token | High |
| 9 | Age of domain | High |
| 10 | Links pointing to page | High |
| 11 | Web traffic | High |
| 12 | Page rank | High |
Identity Theft Detection Models
To prevent identity theft, a fraud detection ML method such as patterns identification can significantly improve the accuracy of fraud detection. For example, if an individual’s behavior patterns are stored to a database. That way, the previous behavior patterns recorded for a certain user are constantly being compared to the activity in the account. In the event that this activity largely differs from the norm, fraud can be suspected. Each new transaction contributes to the behavioral fraud analytics process done by the model, helping it to train better.
Identity theft detection is considered an anomaly detection challenge, so various state-of-art unsupervised Machine Learning algorithms such as LOF, PCA, one-class SVM, and Isolation Forest help find abnormal patterns of a user’s behavior in order to detect unauthorized actions. They work as a litmus test to find anomalies in the field of normal behavior. These algorithms group abnormal behavior data points together in a dense cluster than differs from clusters of normal behaviors.

Credit Card Fraud Detection Models
Fraud models can be tackled with both supervised and unsupervised Machine Learning algorithms. In the first case, traditional classification algorithms are used; in the second case, we can use anomaly detection techniques. The use of neural networks is also efficient, but it requires a great deal of training data with an equal amount of data points for two classes: abnormal and normal. However, in the case of fraud detection, there’s always a lack of balanced datasets.
ARE YOU INTERESTED IN LEARNING MORE ABOUT CREDIT CARD FRAUD DETECTION?
Find out more about Credit Card Fraud Detection with Machine Learning in our Complete Guide
Read Article: Credit Card Fraud DetectionID Document Forgery Detection Models
ID document forgery detection deals, in the first place, with image processing. Certain techniques are used to make sense of the visual information that an image carries. CNN models are usually trained to perform this task, whereas neural networks are built in a way to minimize losses. CNN imitates the work of the human visual cortex — the part of the brain that takes care of processing visual information. Just like how supervised learning needs a collected set of forged and real document images, the dataset needs to have a sufficient number of photos from both classes.
Configuring the neural network to perform at its maximum efficiency includes testing different architecture types with different numbers of layers and filter sizes in convolutional layers. Usually, convolutional architecture has four convolutional layers. This method has accuracy of about 98% for detecting ink mismatch problems in forged documents with blue ink and 88% for black ink.
This forgery detection technique relies on HSI, which is short for hyperspectral image analysis. This method implies building an electromagnetic spectrum map to obtain the spectrum for each pixel in the image.
Another approach may be transfer learning and the usage of pre-trained models such as a VGG16 network based on an ImageNet dataset, ResNet50, or VGG19.
Fake Account Identification Models
Fake account identification is a classification problem, so here we start by selecting the profile that needs to be classified as fake. The most important part of classification is feature selection, meaning that we rely on parameters such as rate of engagement, activity, number of followers compared to the number of people the account is following, and the relevancy of comments. After the feature matrix is built, it is fed into the classification model — which may be one of the most efficient binary classifiers, such as Naive Bayes, SVM, Decision Trees, Logistic Regression, etc. The classifier can be continually trained with new data on fake and real accounts, which helps increase the accuracy of its predictions.
The accuracy of Logistic Regression and Random Forest showed one of the highest results in the approach we used, which is around 90% and 92% (respectively). There’s still a lot to research and test about the problem of fake account identification. The main constraint is privacy laws, which interfere with efficient data collection.
The Benefits of ML for Fraud Detection
Businesses can benefit from ML Fraud Detection solutions in a lot of ways, including:
- Saving time and costs, and reducing human intervention by automating fraud detection activities.
- Improving accuracy, speed, and detection rates.
- The ability to detect fraud in real time.
- Increasing customer satisfaction and loyalty.
- Gaining a competitive advantage over companies that don’t use this technology.
Types of Internet Fraud and How to Prevent Them
Types of Internet Fraud:
Email phishing
Email phishing is a kind of cybercrime that involves spreading fake sites and messages to users, then using the data they share as a result. Email phishing has become a popular and fast way to steal confidential data.
There are traditional methods for phishing detection known as filters. The first one is authentication protection and the second one is network-level protection. Network-level protection splits into three types of filters: whitelist, blacklist, and pattern matching. They work through banning IP address and domains from networks. Authentication protection includes email verification, which implies client-level verification through requiring the completion of a submission from the receiver and the sender.
Apart from traditional methods, which are fading into the past, there are automated methods for Phishing Detection with Machine Learning. These methods are based on classical Machine Learning algorithms for classification and regression. Machine Learning Fraud Prevention is an effective alternative to the traditional methods in this area.
Payment Fraud (credit card and bank loan scams)
Payment fraud detection is the most common fraud type tackled by Artificial Intelligence (AI). Its variations are as diverse as fraudsters’ imaginations. However, here are a few of the most common types of payment fraud: lost cards, stolen cards, counterfeit cards, card ID theft, and card non-receipt. The recent advent of cards with a chip (EMV cards) helped reduce card- present fraud cases in Europe, but not in the United States where the magnetic stripe credit card elimination process is pretty slow.
Identity theft
Information such a victim’s name, bank details, email address, passwords, passport or identification details, and other valuable information to gain access to accounts is under great threat if a professional identity thief comes into the game. Identity theft is a critical form of cybercrime, putting both individuals and enterprises at the risk of unpleasant consequences.
There are three types of identity theft: real name theft, synthetic theft, and account takeover. The collected information is used to register new bank, credit card, and/or mobile phone accounts.
Account takeover: This happens when information is used to gain access to a current account. Sometimes the fraudster may also alter e-mail addresses and other details linked to the account, and the proper owner will not be aware of the changes.
Synthetic theft: This implies merging true information and artificial details to make a new personality. The purpose of this is to make illegal purchases and create counterfeit accounts.
Fraud Detection and Machine Learning for identity theft detection helps examine and check identity documents against secure databases in real-time to ensure all fraud cases will be detected. Valuable documents that can be used for identity theft are passports, PAN cards, or driver’s licenses. To enhance the security provided with Machine Learning, additional verification such as face recognition or biometric information can be required. These security methods demand real individuals to authenticate the operation and significantly lower the chance for successful fraud.
ID document forgery
Before, a person could only buy a fake ID for a lot of money in the black market — but now, with the boom of E-Commerce, various websites offer their forging services for as little as $100 and as much as $3,000 for one document. The lower the price of a fake document, the poorer its quality. Expensive IDs are fabricated so masterfully that it becomes nearly impossible to verify their legitimacy and prevent fraud.
There are ways Machine Learning can prevent fake ID-related fraud. For example, perhaps a criminal downloaded a forged document to prove his personality on an apartment rental site. If the site’s verification system has Machine Learning in it, the photo is scanned by a pre-trained Neural Network. Then, the fraud detection system searches fake document patterns that it has seen in numerous fake documents before, classifies the document as fake or suspicious, and — if needed —additional verification is required.
Fake account identification
Identity verification problems also refer to social media accounts. The process of verifying such accounts includes checking the account registration details, the accessing network, and finally the IP and MAC address of the device creating accounts with the same personality (i.e., photo).
The process of fake account detection depends on the rate of engagement and false activity. It is assumed that fake accounts usually have a large number of friends or followers while their profiles hardly show any sign of user interactions. Also, there is usually a large number of likes, comments, and friend requests from the fake account that are noticeably higher than the average for real users.
These factors relate to users of social media sites such as Twitter, Facebook or Instagram, but it is also possible to identify users who register many inactive accounts on retail or other sites. This can be defined by features such as the date of registration, amount of time spent on the site, and the IP and MAC address of the user’s device.
Credit Card Fraud Detection with Machine Learning
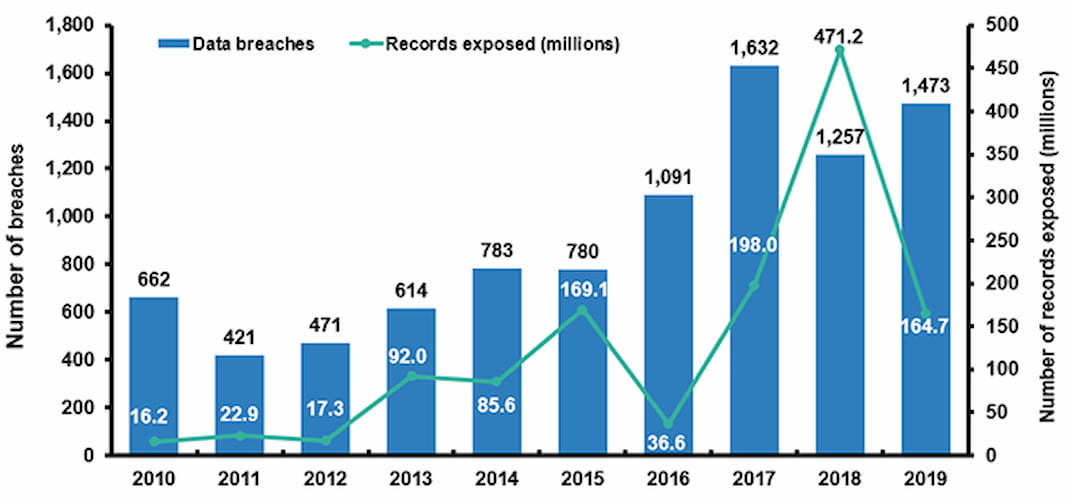
Information on credit cards and payments made online gives fraudsters the opportunity to illegally use it for their advantage. The IC3 report for 2019 shows that victims lost almost $112 million due to credit card fraud.
Credit card fraud is the most common type of payment fraud type, because digitally stored details give the criminal much higher chance to get away with it. Also, transactions are harder to verify.
The table below shows all possible types of credit card fraud activity:
| # | Credit card fraud type |
|---|---|
| 1 | Stolen credit card |
| 2 | Formjacking |
| 3 | Account takeover |
| 4 | Intercepting mailed cards: cards taken from your mailbox |
| 5 | Fraudulent credit applications: using your information to apply for new credit in your name (identity theft) |
Stolen Credit Cards
Online purchases are often the first steps for someone who has stolen a credit card, as this requires the criminal to simply put the credit card’s information into the necessary fields; not all shops require additional verifications. A criminal can also sell the credit card info to other criminals for as little as $45. If you think about it, the income from such trade can be especially large; just consider the data breaches of millions of registered accounts. One such case, the Marriott data breach, happened in 2018.
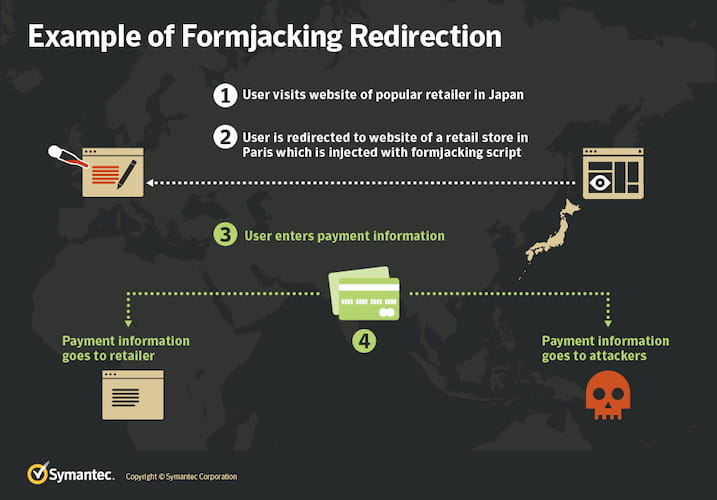
Formjacking
A cybercriminal with skills in how a website’s security system works can inject code into JavaScript that will intercept the card details entered by a user while making an online purchase. This works mostly for poorly built sites with code vulnerabilities.
Account Takeover
Account takeover happens when a criminal manages to access a victim’s account through phishing, malware, data breach, or other methods. A criminal can take over a user’s bank account or social media page to try and ask for money from his or her friends and family. Here are some other ways in which a criminal can take over an account:
- If a criminal somehow learns a user’s login and password for one account, they can try to use a similar password for that user’s accounts on other websites.
- Other cases of account takeover happen through mobile phone scamming, where the criminal pretends to be an official representative of a service that the victim uses.
- If a criminal has access to your mobile phone or email account, he can gain access to valuable accounts through the “account recovery” option — because for most services, it is possible to verify changes via phone message or email.
Intercepting Mailed Cards
After the fraudster has gained access to your mailbox, he or she can find letters with valuable information about the bank accounts and credit cards you use.
Fraudulent Credit Applications
Criminals can take out credit in your name if they obtain enough information. After a while, you will receive upsetting messages saying that you have a debt you never took out.
Widespread Fraud Scenarios
By knowing the principles of how a fraudster operates online, Machine Learning engineers can develop efficient techniques to detect fraudulent activity.
Here are five widespread fraud scenarios that are taken into account when using ML for fraud detection:
Advanced Privacy Software
Experienced fraudsters use special software that hides information about the user, such as the user’s location, from browsers. Software like Anti-Detect and Kameleo is used to create several instances of virtual machines in browser windows.
Location Spoofing
Simulating the location typical for a card owner, the fraudster can avoid the rule-based security system built in to a site. He can determine the necessary location from the compromised card details.
Phone Number Spoofing
If a fraudster somehow obtained the card details of the victim, he can buy his phone number online. Then, to deal with the problem that he does not physically have this mobile phone, he can call the customer’s phone provider and inquire about diverting all purchase information from the card to a new phone number.
Copying a Buyer’s Behavior
At times when criminals were less sophisticated in the “art” of credit card fraud, they used to charge large amounts of money and buy expensive goods immediately after compromising the card. It was easy to spot fraud in such cases. Nowadays, they tend to simulate a “real customer’s” behavior, making smaller purchases before a big one or pretending to think before buying something through adding and removing things from the user’s online shopping basket.
Find out more: Customer Behaviour Analysis Using Machine Learning
Enhanced Customer Information
To appear more convincing while trying to compromise a user’s credit card, fraudsters buy and sell device IDs and driver’s licenses on the Dark Web. This allows criminals to mix valuable information about a certain person and build a new account based on the fake IDs.
Fraud Detection in Banking and E-Commerce
E-Commerce
E-Commerce businesses are the most vulnerable to online payment fraud as long as it is not necessary to have a physical card if you make a transaction online. Starting from small niche retailers to large providers, their websites are under the threat of formjacking or undergoing a data breach. Even huge E-Commerce businesses such as British Airways, Newegg, and Ticketmaster are exposed to attacks on a daily basis.
Read also: Marketplace Platform Development Guide
Seventy percent of card fraud in Europe is represented by card-not-present fraud. Consequently, the number of fraud cases linked to online E-Commerce is rising, while the E-Commerce market is predicted to reach around $4.5 trillion in 2021.
An E-Commerce business can prevent fraud by constantly improving the internal network security system, such as setting a more advanced system based on fraud detection. The main advantage offered by Machine Learning algorithms for fraud identification is a strong performance in the real-time value detection rate. The second thing to consider is that Machine Learning models tend to spot fraudulent E-Commerce transactions at a higher speed without increasing the frequency at which genuine transactions are declined.
Banking
According to research, venture funding for fraud and cybersecurity AI-based web and mobile applications development will increase by 30% in 2020. Banks are usually interested in decreasing the amount of payment, loan, and customer onboarding fraud.
One example of how fraud detection software can work for banks is developing risk profiles for bank customers and rating them on granular data. A bank can either allocate its current software developers to work on such a tool or outsource data science professionals to build Machine Learning models that take widespread fraud schemas into account.
The Process of Using Machine Learning for Fraud Detection and Prevention
This is an iterative process that includes several essential steps. Here is a quick overview:
- Collecting data on the transactions or activities you want to monitor for fraud.
- Preprocessing data (including handling missing values, outliers, and duplicate records) and feature engineering.
- Splitting data into two or more subsets, for example, training data, validation data, and test data.
- Feature scaling and selection.
- Selecting the appropriate model.
- Training the model using the dataset.
- Evaluating the model to assess performance.
- Addressing class imbalance, if present.
- Adjusting the decision threshold for classifying transactions as fraudulent or legitimate.
- Deploying the model.
- Setting the feedback loop.
- Defining and implementing the post-detection actions.
- Documenting the model and its performance.
- Improving the model continuously.
The Final Word
As long the modern world is overwhelmed with card-not-present transactions online, the Banking and Retail sectors are under threat and face many fraud cases. Email phishing, payment fraud, identity theft, document forgery, and fake accounts contribute to the high level of criminal attacks on vulnerable users’ data and lead to data breaches. As old rule-based algorithms for fraud detection fade into the past, new top-notch methods based on Machine Learning algorithms for fraud detection and prevention are bringing greater value to businesses with their real-time work, speed, and efficiency.
Further Reading
- Data analysis techniques for fraud detection
- Machine Learning for Fraud Prevention: What’s Next
- Machine Learning in Ecommerce Fraud Detection
- Machine Learning for Unsupervised Fraud Detection
Ready to speed up your Software Development?
Explore the solutions we offer to see how we can assist you!
Schedule a Call