

Introduction
The more the businesses know their customers, the better. To provide the best customer experience, you need to know as much information about your customers as you can. Getting this information is pretty hard if you use traditional methods. However, with the power of Artificial Intelligence, it could be much more effective. Seventy-five percent of companies that have implemented AI and its subdivision, Machine Learning, are boosting customer satisfaction by more than 10%, according to Forbes.
Analyzing customer behavior with the capabilities of AI could save an enormous amount of time, compared to human employees. All the errors that people could make would be eliminated. But that doesn’t mean that data analysts are becoming useless. No, the experts in this scenario will be used for more sophisticated tasks, while machine intelligence will take on routine ones.
Gartner reported that AI-driven business value will expand to $3.9 trillion in 2022, while 40% of the work of data scientists will be automated by 2020. That means that 40% of the work of human experts will be automated, giving room for more nuanced activity. But that’s the future; let’s look at the current situation on the market.
Don't have time to read?
Book a free meeting with our experts to discover how we can help you.
Book a MeetingCustomer behavior analytics for retail
Nowadays we are witnessing a very exhausting battle. There are an enormous number of companies and brands competing to hear and understand their customers faster than their competitors. While businesses are used to reacting to customer interactions, events, and behavior in real-time or after the fact, it’s getting obvious that it is not enough. To keep user experience at the highest level possible, something else must be done.
That’s where Artificial Intelligence comes into play. This technology has all the potential to transform the way retailers interact with customers. In particular, AI solutions development can offer deep CRM analytics, more valuable insights on customer behavior, expectations, tastes, and wishes. If done right, AI can empower companies with the ability to offer the right products in front of the right clients when the time is right.
Unfortunately, companies invest in strategies and tools that are built to react to customer interactions. As a result of these methods, customers receive products and offerings that are already slightly or completely off track with their current preferences and wishes. No wonder it turns into lost opportunities, waste of resources, lack of Return On Investment, and less revenue.
Intelligent analysis of customer behavior is the only thing that can change this scenario in 2020. Relying on guesswork is next to impossible to make an accurate prediction on a potential purchase, the success of a certain marketing campaign, or the ability to create unique and personalized individual customer experiences.
What makes Artificial Intelligence for customer behavior analysis great
Artificial Intelligence and Machine Learning are specifically what retailers and marketers need. Advances in these technologies allow the segmenting of content and products for customers based on analyzing and understanding their purchasing habits. But personalization is not effective enough. Retailers need solutions and tools that will individualize interactions with customers and increase brand loyalty.
AI can provide individualized customer experiences by forecasting how customer behavior will influence current business models, and help change marketing campaigns.
This could be achieved by AI/ML data analytics tools that are able to offer projections of metrics like customer loyalty, affinity, estimated transaction value, and purchase probability. This information could be used by marketers to adjust their campaigns on the fly, allowing them to change tactics, individualize offers, and decide what to do next.
Artificial Intelligence and Machine Learning offer some obvious and clear benefits for retail businesses. With the power of these technologies, marketers would be able to correctly forecast the value of individual customers, as well as the potential revenue from certain segments of the client base. As a result, marketing budgets will be spent more effectively and generate more profit for retail businesses.
The challenges
While all of these advantages and benefits are obvious, the road to worldwide adoption is still long. At the moment, only 37% of retail organizations are working on the potential implementation of Artificial Intelligence and Machine Learning. That’s probably because many still don’t clearly understand how AI could help them reach customers. A cultural shift must occur. Retailers are used to being reactive, and changing the way they operate will not be an easy task. More than that, brand marketers are forced to get results from existing methods and marketing campaigns. Artificial Intelligence needs some room and time to flourish.
These reasons make some business leaders think that the introduction of Artificial Intelligence is too complex. And there is some truth to that. However, to get the most value out of AI in Retail, companies should put in the time and effort to launch a clear AI strategy across the entire organization. If you find the right implementation of Artificial Intelligence for your business, this can bring to life all the benefits and business value we are talking about in this article. Let’s look at some real-life use cases of AI in Retail.
Customer behavior analytics use cases
We have reached the point where technology is able to determine the tastes and interests of thousands of people, which results in precisely targeted marketing campaigns.
A world-renowned sports brand achieved an impressive sales increase after implementing Kimola’s platform. The goal was to understand which stores in Istanbul should be rebuilt to attract more soccer fans. Profiles on social media were fed to Machine Learning algorithms to decide what really defines a soccer fan.
The platform located 50,000 true soccer fans and investigated the things they are interested in. As a result of this research, it was determined that the most convenient place for the store is on the outskirts of the city. So the brand focused on remodeling this particular store with a 100% soccer theme and got a 210% sales increase.
AI-powered customer behavior analytics could be location-based. Another brand that implemented Kimola’s platform was looking to find the areas where their customers would like to spend time. Kimola’s algorithm analyzed 100,000 social media users to determine exactly where marketing efforts would be successful. Based on the research, the brand placed more of its products in the shops where the customers would most likely visit. This resulted in a 42% brand visibility increase and the sales that come with it.
Predicting customer behavior
Correctly predicting customer needs is priceless for marketers. Maybe assumptions worked well in the past, but now we have the era of data-driven insights extracted by Artificial Intelligence and Machine Learning algorithms. They can do it significantly more precisely than humans and can even build long-term predictions.
It is already possible to take information like customer sentiment analysis based on social media and make forecasts for months ahead. Marketers don’t have much time to figure out this innovation, experiment with it, and understand how to get value from it. Because their competitors are already implementing Artificial Intelligence and Machine Learning for customer behavior prediction.
According to research from Protiviti and ESI ThoughtLab, most companies are only starting to implement AI. But at the same time, the majority of them are very quick with adopting it. In the next two years, significant leaps are expected as those businesses learn how to gain revenue from the technology as well as progress in marketing campaigns and improved customer experience.
But for Netflix, this is already a reality. Eighty percent of the content that their subscribers watch is already generated by an AI-driven recommendation system. There are also some estimations that algorithms help to save $1 billion annually on customer retention. Amazon is also using Artificial Intelligence to predict where to stock products and place them as close to possible to potential buyers.
AI-based customer behavior prediction model: hands-on explanation
AI-based customer behavior prediction models are effective working with unstructured data and identifying hidden features and similarities to make groups of data samples united by common traits. These models can also predict prices, demand, or weather. AI can make customer behavior predictions by segmenting customers into groups, as customers with similar features will likely have similar buying behaviors.
The group’s customers are divided into Clusters. Subsequently, the process of their division is called Clusterization (a term used in Machine Learning). Speaking in technical language, every customer corresponds to a data point in a Cluster. It can be visualized on a chart with Python visualization tools. When Clusters are defined, customer points might look like this:
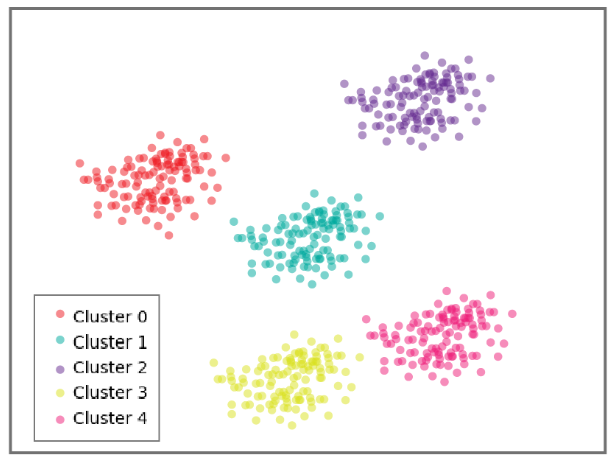
You can infer that points are usually united into Clusters where they are located close to one another. Anyway, the situation shown in the picture is quite idyllic. All Clusters are neatly separated with a big distance. But in reality, the task can be much more complicated. For example, when data points intersect each other and are very densely located; this makes it hard for a Machine Learning developer to draw a line separating them.
Customer demographics such as gender, age, annual income, and spending score are usually taken into account to evaluate their similarity.
These are just a few most obvious customer features, but a good data scientist can detect more hidden and subtle traits and contribute significantly to the power of Clusterization.
Getting into even more technical details, two common Clusterization methods for customer behavior analysis that work with unstructured data and refer to unsupervised learning are Centroid-based Clustering and Hierarchical Clustering. Methods such as K-means and DBSCAN belong to Centroid-based Clustering, which means that a developer should initialize center points for each Cluster. Then, the data points that are the closest to a certain Cluster center are assigned to this Cluster. Agglomerative Clustering belongs to Hierarchical Clustering and has a different way of working — in this method, each data point is a separate Cluster at first. The closest Clusters are merged into a single Cluster, then the closest pairs of Clusters are merged into a single Cluster, and so on. This process stops when we have the exact number of Clusters defined by a developer.
When it comes to grouping tens or hundreds of thousands of customers corresponding to data points on the graph, they are usually represented in 5, 10 or even up to 500 dimensions that are hardly comprehensible to a human brain, let alone possible to visualize all at once. This happens because every customer’s feature equals a separate dimension. Here, Machine Learning Engineers use such a technique as Dimensionality Reduction, which decreases the number of features if they are abundant.
Now that we have covered the conceptual image of what is used to create a Customer Behavior Analysis, let’s dive into the technical implementation step by step:
First, we have our data on Customers with their IDs and other important features.
The next step is to Collect the data into a panda’s DataFrame and explore the data manually.
Here, developers analyze the quality of the data and the distribution of variables. The main thing is to identify whether you have Missing data. Missing data is when some features in columns corresponding to customers, such as gender, age, annual income, etc., have zero values in the rows relevant to them:

Dealing with missing data.
Before running the Clusterization algorithm to divide customers into groups by similarity, we have to somehow replace those values that are missing. There are many methods to do that:
Imputation using mean/median values
This is when you calculate the mean/median values for non-existing data points of a certain feature column, e.g., “Age”, and then replace all missing values in this column with the number you have. This is not a very accurate method, since it does not count the correlations between features — although, it’s fast and easy.
Imputation using the most frequent values
Here is one more easy method to replace missing values – simply put the most common numbers/categories in the place of the missing ones.
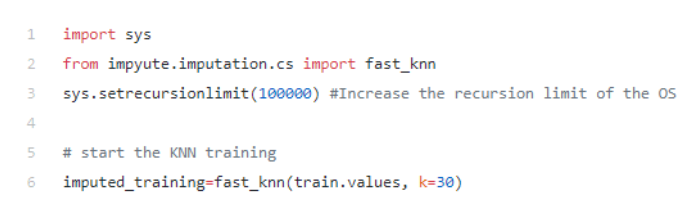
Imputation using k-NN
The K-NN method that we already described as one of the unsupervised Clustering techniques also can be used to deal with missing values. But how? The algorithm relies on the “feature similarity” between data points, in other words, it “looks” at the data point that is the closest to the other one on the graph, and uses its value for a data point that is missing one or more values.
We think that the K-NN imputing method is the most beneficial out of those we mentioned, so we usually choose it when it is necessary to manually replace missing values.
The Impyute library is used for this (see a sample below):
There are many other imputation methods with varying pros and cons, but we are not going to stick to this topic. Let’s go to the next phase of customer behavior prediction with Machine Learning: Dimensionality Reduction.
Dimensionality Reduction can be done in two ways:
- We can identify the most valuable customer features and exclude the rest.
- We can extract new customer features through combining the existing ones.
The second way implies a process of Feature Extraction; that is what we usually do when we have to deal with multi-dimensional features. Feature Extraction can be done using many techniques:
- Principal Component Analysis
- Independent Component Analysis
- Linear Discriminant Analysis
- t-distributed Stochastic Neighbor Embedding (t-SNE)
- And others.
Let’s look at PCA.
Principal Component Analysis (PCA) is one of the most popular techniques for Dimensionality Reduction. It helps extract information about the hidden structure of the dataset. PCA can visualize n-dimensional features into whatever dimension choose, whether that is 2-D or 3-D.
Now, let’s move straight to Clusterization.
Clusterization with K-means.
After vectorization, we have information on customers (represented in data points) scattered all over the space. To know if two data points are similar, we need to calculate the distance between them. There are various distance measuring methods used for this task such as Manhattan distance, Minkowski distance, Euclidean distance, and others. The K-means algorithm uses Euclidean distance, which is a quite simple formula for calculating the distance between vectors. Most people learned this in school: squared differences between corresponding elements of the two vectors.
Before we start the K-means model, we need to state the number of Clusters we want. Different number of Clusters give entirely different results. To learn how many Clusters we should choose, the elbow and silhouette methods are used.
The Elbow method considers the total intra-cluster variation, which varies regarding the number of Clusters (the total within the Cluster sum of square) and tries to minimize it. Then we calculate the k-means for a range of various values of k, where k is the number of Clusters.
The main idea of K-means is to choose a center for each Cluster randomly at first and then calculate the distances between centroids (Cluster centers) and the points around them. If the distance is minimum, the point is assigned to this Cluster. After that, the new Cluster center is recalculated and the point that is in the middle of every Cluster is chosen as a new center. We repeat this process until the Cluster centers do not move anymore. Let’s see what the Clusters look like:
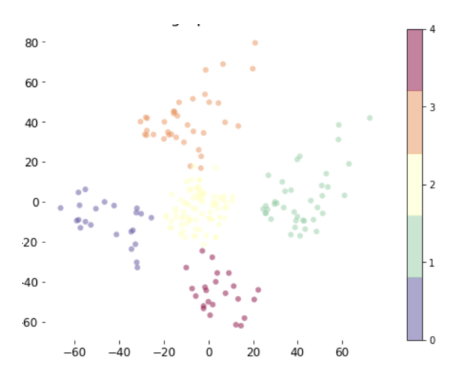
Getting back to our initial aim — to segment customers into groups, so we can predict their buying behavior and offer them suitable products. The center point of each Cluster shows the average customer of that group.
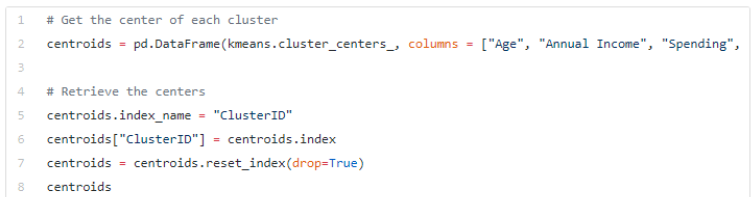
The most interesting part of the modeling results lie in this Dataframe:
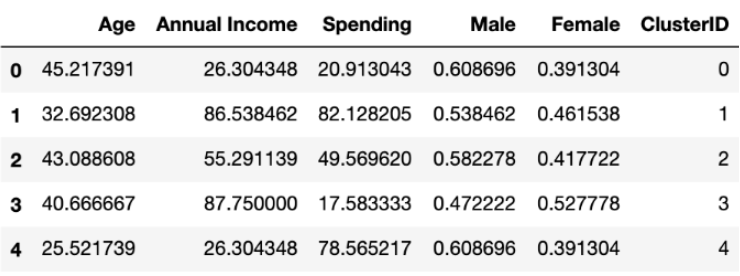
Here we see the values assigned to five groups of segmented customers, where features such as “Annual Income” and “Spending” appear to be the most important for us. On the other hand, the “Gender” feature does not really have an influence on customer behavior.
Let’s sum up our results:
- Customers with spending and earning that are relatively equal are in the “0” group;
- Customers who earn a lot and spend the same belong to the “1” group;
- Customers who have average earnings and still have quite large spending amounts are in the “2” group;
- Customers who earn a lot, but spend only a little were assigned to the “3” group;
- Customers with low earnings and high spending rates belong to the last “4” group.
Using this information, we can now regulate marketing strategies for different customer types and offer them relevant discounts and products.
Conclusion
That’s all we have on the current state of Artificial Intelligence and Machine Learning in the Retail Industry in regard to customer behavior analysis. We dove deep into the AI-based customer behavior prediction model, so you see how it works in detail and how it can benefit your business. There are plenty of other ways AI could benefit your organization such as Predictive Maintenance, read The Complete Guide to Predictive Maintenance with Machine Learning to find out more about this topic. If you are interested in anything we’ve discussed or have questions on Artificial Intelligence development, feel free to contact us at SPD Technology. We have all the necessary expertise and experience to take ownership of your project and help you on every level: from consultations or workshops to full-scale AI project development to benefit your business. We believe this is the right time to introduce Artificial Intelligence to your retail business!
Ready to speed up your Software Development?
Explore the solutions we offer to see how we can assist you!
Schedule a Call